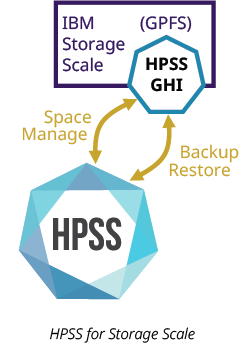
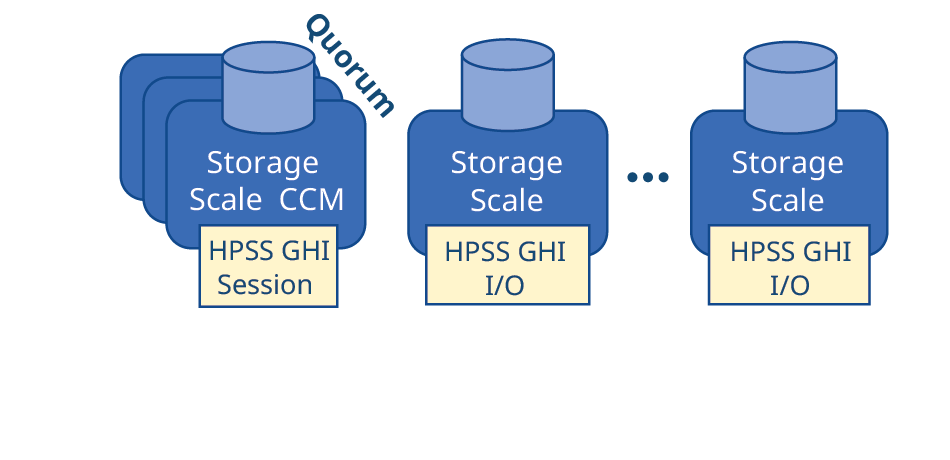
HPSS GHI leverages Storage Scale’s information lifecycle management (ILM) policies and provides a complete solution to copy file system data to tiers of less expensive storage (disk and tape) managed by HPSS. When space thresholds are reached, HPSS GHI will automatically purge the older (unused) files, from the file system to free space for more data. However, purging files is not deleting files: purging removes the data blocks while leaving the metadata behind, so the Storage Scale name space remains whole. When accessed, files are automatically recalled from HPSS for normal use in the file system.
HPSS GHI can be configured to collect many small Storage Scale files into much larger, tape-friendly HPSS aggregates. Doing so gives HPSS two advantages: (1) When collecting thousands of files to a single HPSS aggregate, the file-operations-per-second burden on the HPSS name space goes away; and (2) small-file tape transfer-performance goes up. In addition to improving small-file tape write performance, a small HPSS disk cache for these small-file aggregates enables HPSS to achieve high-bandwidth tape-reads, because HPSS can be configured to recall the entire small-file tape aggregate back to the HPSS disk cache. This allows HPSS GHI to work with the lower-latency HPSS disk cache rather than the higher-latency HPSS tape drive for small file IO.
Because HPSS disk and HPSS tape are not licensed by capacity, it may be more economical to add more HPSS block storage units, rather than provisioning the file system with additional capacity, which increases the file system license fee.